Learning about Consensus Algorithms
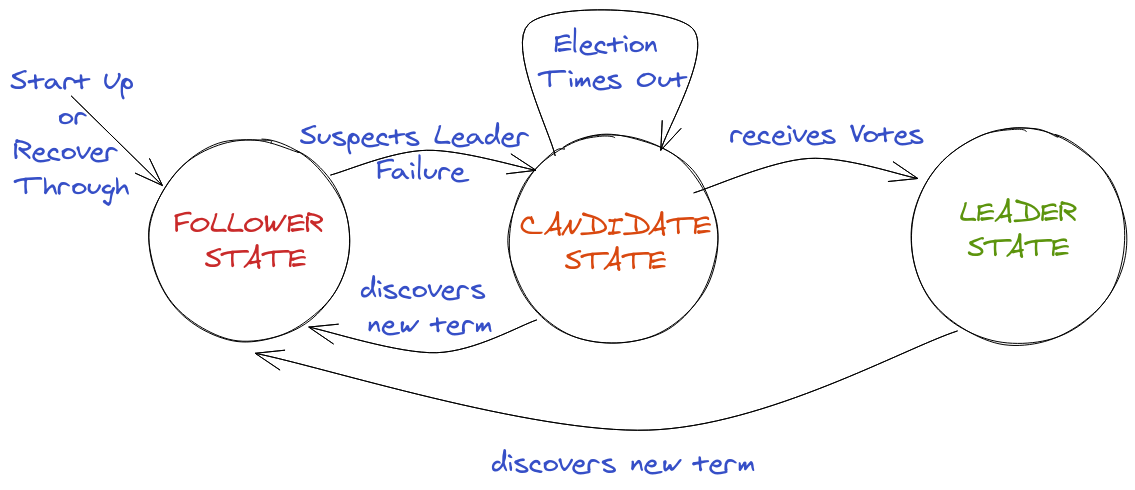
That's a handful of State Machine Diagrams!
Consensus Algorithms in Distributed Systems is that aspect which makes sure, all the instances of the software that you are running are consistent with each other, and are not serving stale data. Consistency, which makes sure that all of the data are up to date, and not serving stale data, which means old data is invalidated by the software and not served, instead is synced up with other instances.
Let's build up the basic terminolgy and concepts before we dive into Consensus Algorithms!
Availability, Partition and Consistency: The CAP Theorem
There is this cool guy - Eric Brewer who came up with this theorem, which is basically simple -
Out of Availability, Partition and Consistency, you can only atmost two guarantees for a distributed data store.
Let's break this down -
-
Availability - Availability means that your system is accessible all the time. You can make this sure by running multiple instances of your software, so that if one is down, the others are there to back you up!
-
Partition - Partition non-trivially(atleast for me!) stands for Network Partition. We can have Network Partition, if we have two instances of software running, and each of them are un-synced(don't have any communication) or have a network barrier. It is difficult to serve the purpose of software, if we have a network partition, the user needs to be rerouted to another instance with up to date data.
-
Consistency - Consistency, as you would have guessed it, stands for maintaining the same state among all the software instances. Imagine a bank ATM, and this should be strongly consistent so that whatever money you withdraw/deposit is quickly reflected among all the instances of ATM Machines.
So all in all, you can have atmost two guarantees out of three namely - CP, AP, CA. In practical situations, you want your software to run inspite of Network Partitions, so you only get to choose CP or AP.
Eventually Consistent Systems
You might have heard about big tech companies bragging about how their software is equally highly available and consistent. Note that I haven't used strongly consistent, and this has its own implications.
These systems are eventually consistent, which makes sure the data is synced with each other(or if conflicts happen, we arrive at the reconcilation eventually). This means when our data is updated at place A, if we query the same data from place B, it might take some time before the similar data(or state) is shown.
Note that distributed systems is all about trade-offs, and this might not be bad trade-off at all, if we all want highly available systems, and consistency being eventual also works for us.
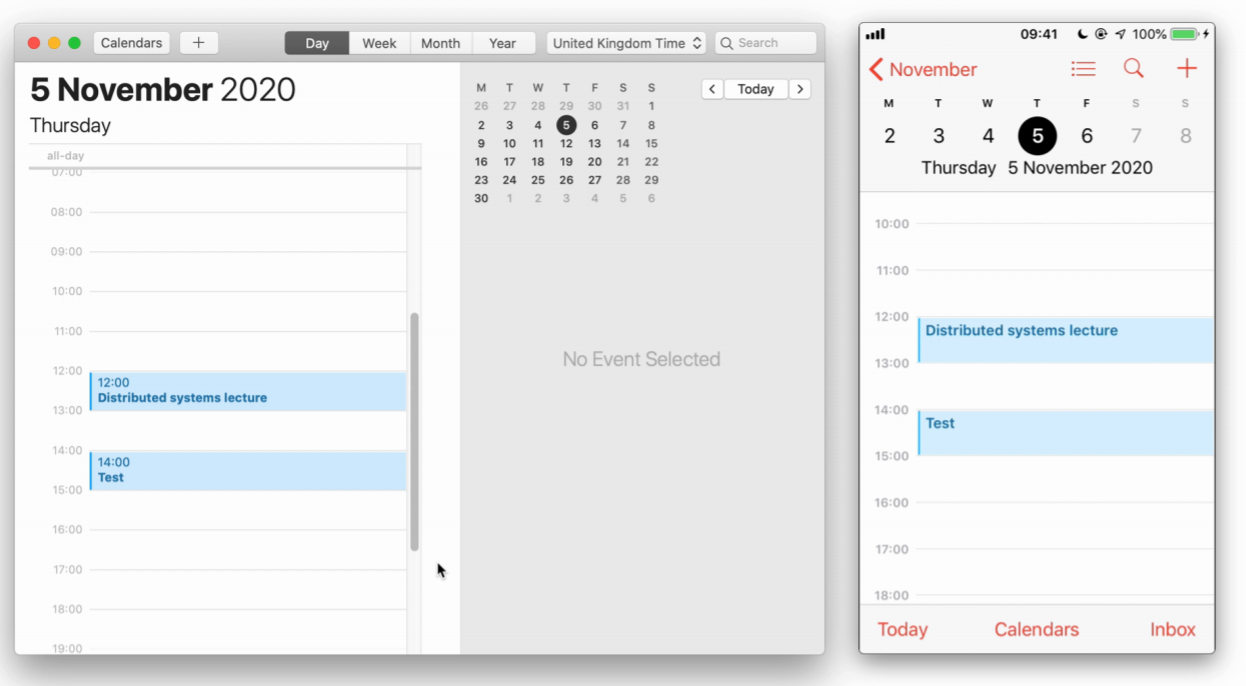
Calendar sync-ups are not always immediate, that's the result of Eventual Consistency
To demonstrate an example, lets use Google Docs - we would want our data to be replicated among all the instances, and should be highly available. At the same time, the data doesn't need to be strongly consistent; we can have eventual consistency, and this would work well for us. So effectively, its about the use case that we want, and not the one size fits all policy that we should worry about.
Consensus Algorithms: For Strong Consistency
Let's say, we want to provide CP guarantees for our software, so how should we proceed with this?
Consensus Algorithms make sure that our data(or state) is consistent across all of our software instances. In case we want to provide Strong Consistency guarantees, we need to return back to our whiteboard, and figure out one.
The generic way how a consensus algorithm works is that -
- We elect a leader among a bunch of instances, and whenever we perform a write operation, we get a majority of votes, before we commit that.
- Majority is required so that the state of the leader is consistent with other systems, while we make sure that, if the system that goes down, it can catch up with the state of the leader through majority, thus providing a strong consistent systems.
There are lots of pitfalls and gotcha moments while you design an algorithm for consensus - In an ideal world, you would not have any network failure, and bunch of network calls should return a response(success/failure). We should always have a majority(in an ideal world, if more than majority of systems fail, we cannot handle the transactions; an implication of non-available system at the cost of strong consistency).
Common methods of overcoming the shortcomings
We know that in practical world, we cannot work with the assumption of a happy path. We need to take care of the shortcomings -
-
Network Failure - Network failures are a fair assumption; packets can get dropped, messages might get spoofed, data might get duplicated and so on. We need to make out communication reliable by using TLS(which makes communication secure) and retrying with backoff so that our data reaches the server at least once. We can also make our communication idempotent, so that duplication of transactions, doesn't hamper our system.
-
Causality - Causality states the relative ordering of two events occurring. This is derived from Physics, and lays the ground rules of how the timeline of events can be described(or not) -
- When A->B, then A might have occurred after B (A->B means A occurred after B)
- When A||B, then both the events are concurrent(might happen at the same time)
We need to make sure that the ordering of events doesn't impact our ordering of transactions, so we use the concepts of clocks described below.
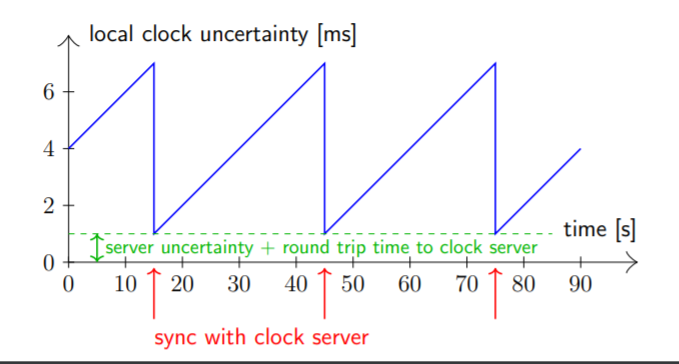
Clock Skew between global clocks and local instance rises monotonically until it is synced
- Clocks and Global Clock - It is important to have a global clock to make sure we can order the events. Note that this introduces several shortcomings with this approach - single point of failure, clock skew and round trip time to sync clocks. We should also note the cost associated with maintaining this setup. Often we use some sort of techniques like Hybrid Logical Clock.
Consensus and Total Order Broadcast
Before we move on to Consensus, let's talk about Total Order Broadcast.
Total Order Broadcast states that if m1 is delivered before m2 on one node, then m1 must be delivered before m2 on all nodes.
A common example is depositing and withdrawing money. The ordering matters, as the reverse order(withdrawing and then depositing) won't work for our case.
Consensus is a formal equivalent of Total Order Broadcast. We would certainly want these behaviours -
- Several Nodes want to come to an agreement about a single value.
- Once all Nodes decide on a certain message order, all nodes will decide the same order.
Common Consensus Algorithms -
- Paxos - Single Value Consensus
- Multi-Paxos - Generalisation to Total Order Broadcast
- Raft - FIFO based total order broadcast
Raft - The Consensus Algorithm
Phew! Finally, we have built the stage to talk more about Raft.

The Raft Mascot :P
Raft is a FIFO based Total Order Broadcast based Consensus Algorithm. Here is a nice visualization to play for understanding about raft. The co-author of this algorithm Diego Ongaro has a nice video about it.
I will be talking more about Raft in my next blog, and would also describe my thought process of writing a simple implementation for Raft.